
操作系统复习
用来复习操作系统考试,写的更多是我觉得比较有意思的点或者做题套路,想到哪儿说到哪儿,可能乱七八糟的不太具有系统性,夹杂了很多个人理解的东西。
概览
操作系统:建立在硬件层上的第一个软件。如果说计算机组成原理研究的是冯诺依曼结构的计算机的各个组成部分以及各种资源(CPU、内存、硬盘、IO),那么操作系统研究的就是如何管理这些资源,或者可以说成是一个资源管家,确保各项资源得到有效利用,同时为用户提供操作计算机的接口和支持。具体来说,就是如何用好这些已有的资源,如何协调工作。而各种调度算法也是为了提高资源利用率,为了更好、更快地完成给定的计算任务。说直白点,最大的目标就是更好、更快。事实上操作系统也将对系统资源的使用抽象封装成一个个函数接口,这就是一直说的 syscall,这也变相地降低了编程和开发的难度。操作系统对 syscall 的封装,也实现了硬件无关性的功能,开发人员不需要关心底层使用的计算机体系结构(x86/ARM/RISCV)是怎样的,各种物理设备又有怎样的特点。所以不管从事什么样的开发,我觉得了解底层的代码实现是很有必要的,而不仅仅做一个API caller,也就真的只是所谓的“码农”了。
进程管理
进程很像游戏存档、读档的过程。
上下文切换的两种原因:
- 用户调用syscall,进行慢操作,此时进程进入阻塞态
- 时钟中断,属于进程的时间片使用完了,触发中断
共享内存是把同一个物理内存区域同时映射到多个进程的内存地址空间的通信机制,即一个物理页被挂载到了多个进程的页表中。
中断向量表:想象成一个函数指针数组。
中断向量表的主要特点和作用包括:
- 中断向量:中断向量表包含了一系列的入口地址,这些地址指向与特定中断类型相对应的处理程序(ISR)。每当发生中断时,处理器会根据中断类型查找中断向量表中对应的地址,并跳转到该地址执行中断处理程序。
- 硬件和软件中断:中断既可以由硬件(如按键、定时器、外部设备)触发,也可以由软件(通过执行特定的中断指令)触发。
发生中断的一系列流程:
- 捕获中断,保存当前进程的上下文
- 切换CPU特权级,进入内核态
- 根据中断向量表跳转到对应的中断处理函数
- 恢复现场,回到用户态进行执行
关于线程的理解
中断的最小粒度:一条机器指令,指令执行中是不会被打断的,即单条指令的执行是一个原子性操作。注意这里的指令不是高级语言中的一行代码,例如对于c语言代码片段 if(x==0) ,可能会转换为一些用于比较x和0的指令,以及根据比较结果进行跳转的指令。(即一对多的情况)所以在此情况下,即使一个简单的if判断也可能会被中断,并切换成其他线程/进程。
所谓共享内存,是把一个物理页挂在多个进程页表项上。极端情况:某两个进程的页表项全部相同,则所有地址空间共享–>线程。
地址空间是共享的,但pc和一整套寄存器的值以及栈区状态是不同的。每一个进程都有自己的地址空间和页表。进程切换相较于线程切换,需要额外加载地址空间,把顶级页表的地址放入cr3寄存器(在x86体系结构中)。对于已经加载到内存中的同一可执行程序,执行流执行到不同的地方可以形成多个线程。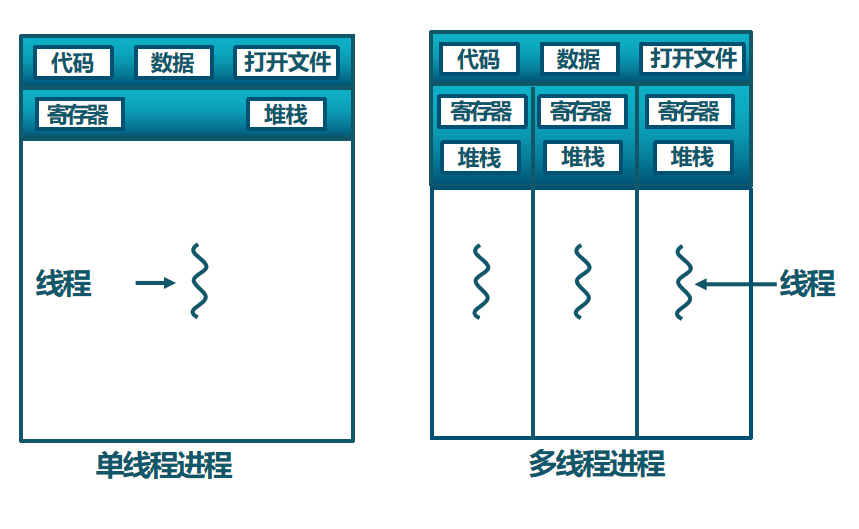
操作系统的内核代码是不会被中断的。OS中设计了三种可以在运行时“呼叫”操作系统,并提升权限的方式。
- 中断(Interrupt):来自硬件设备的处理请求,如时钟中断
- 异常(Exception):非法指令或者其他原因导致当前指令执行失败
- 系统调用(System Call):应用程序主动向操作系统发出的服务请求,主动“呼叫”OS的编程方式
一个进程进行一个I/O请求,调用syscall,进入到阻塞态,OS调度其他进程,当I/O操作完成后,I/O设备会向CPU发送一个中断信号。这个中断通知操作系统I/O操作已经完成。OS再将这个进程转移到就绪态,然后进行调度算法选一个就绪的进程运行。
进程间通信IPC(Inter-Process Communication)
主要涉及同步/异步、阻塞/非阻塞通信的问题。消息队列则相当于一个数据缓冲区,发送方负责把数据放进去,接收方负责拿出来,这个过程可以是异步的,
先给两个定义:
- 临界资源:一次仅允许一个进程使用的资源。
- 临界区:进程中访问临界资源的一段需要互斥执行的代码。
同步与互斥问题产生的根本原因:在线程的世界里互相感受不到对方的存在。共享地址空间的线程会产生新的问题—同时读写某一变量/内存?
简单的思路:用一个flag标志来标记某一变量x当前是否被读写,每个线程在写数据之前先用if语句判断标志位是否为1,为1则等待,不为1则进入语句块中写数据。问题在于,判定–>设定/修改的过程中可能会被中断打断。进而切换成其他线程。核心思路:判定+设定 两步操作不被分割,原子化。实现思路的方法:
- 硬件层面增加TSL(Test and Set Lock)指令,即在体系结构和指令集层面增加一种指令,一次性完成判定+设定的操作。
- 软件层面禁用中断。即:禁用中断–>判定–>设定–>打开中断。但这种方法并不能使用,原因在于用户态程序没有开关中断的权限。(也不敢将权限交给用户程序,大可以关了中断之后再也不打开了,之后一直执行这个用户进程,纯粹土匪了属于是)
- Peterson算法。
问题:每一条指令执行后都可能发生上下文切换,需要各种发生中断位置的排列组合来验证会不会出现互斥问题。
两种等待方式:
- while(true){if……} 持续判断标志位是否置为0,这种方式也称为忙等待。但这是在单核CPU上不希望被看到的,因为在白白浪费CPU资源。说直白一点,就是
占着茅坑不拉屎 - 一次if判断,如果标志位为0则直接sleep阻塞进程。之后等待被唤醒。相较于上一种方式付出的代价:上下文切换带来的开销。
让权等待:当进程不能进入临界区时,应立即释放处理器,防止进程忙等待。
针对之前提到的软件层面禁用中断的问题,可以将开关中断的操作交由操作系统完成,于是有了信号量P/V(信号量表示一种资源。P就是wait操作,等待资源,V就是++操作,释放资源)。这里不放详细的代码定义了。
- 对于竞争问题,进入临界区需要 P 一下,离开临界区需要 V 一下。信号量初始为1或者可用资源数。P想象成上锁过程,V想象成解锁过程。
- 对于同步问题,简单说,对于信号量 S, P(s)后的代码一定会在 V(S) 之前的代码之后执行。信号量初始为0。eg: procA的x代码片段要在procB的y代码片段之前执行。
则A:……x;V(S);…… B:……P(s);y;…… 要用什么,P一下;提供什么,V一下
互斥同步关系均存在的时候,实现互斥的操作应在实现同步的操作之后,否则可能死锁。比如先P声明要进入临界区,之后P阻塞等待资源,结果另一个线程也进不到临界区,也提供不了资源,然后两个都G了。
信号量机制存在的问题:编写程序困难、易出错。于是,产生了一种新的进程同步工具—-管程。组成:
- 共享数据结构
- 对数据结构初始化的语句
- 一组用来访问数据结构的过程(函数)
- 各外部进程/线程只能通过管程提供的特定“入口”才能访问共享数据。这个”入口“其实就是指对该数据结构进行操作的一组过程(或函数)每次仅允许一个进程在管程内执行某个内部过程。
核心思路就是把共享数据的申请和释放放在一个统一的接口上。从而保证访问互斥。
死锁问题
简单说就是进程A持有资源y,等待资源x;进程B持有资源x,等待资源y。于是两个人都一直等,这跟数据库和网络中阻塞Receive其实是一样的。上图: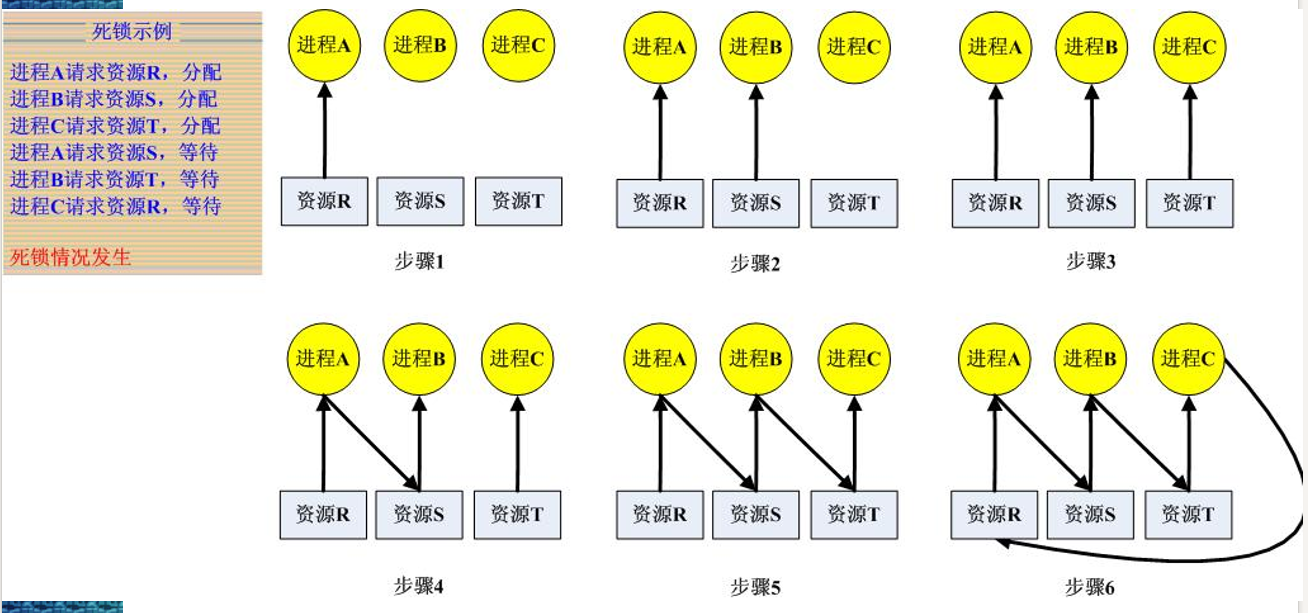
内存管理
内存按字节编址,即内存中的“1”代表1个字节。
未引入分页机制前,我们先考虑下面的情况————连续内存分配:即程序需要1个G,就在内存中连续申请1个G的大小。
- 分配时:寻找空闲分区,分区大小应大于或等于请求进程的要求:若大于,则将该分区分割成两个,其中一个标记为“占用”,而另一个标记为“空闲”.
分区回收算法主要完成: - 回收时:查阅当前分区状况,完成不同的回收操作。
几种不同的分配算法如下:
个别来看,外碎片较小,整体来看,会形成较多外碎片。但较大的空闲分区可以被保留
随着低端分区不断划分而产生较多小分区,每次分配时查找时间开销会增大。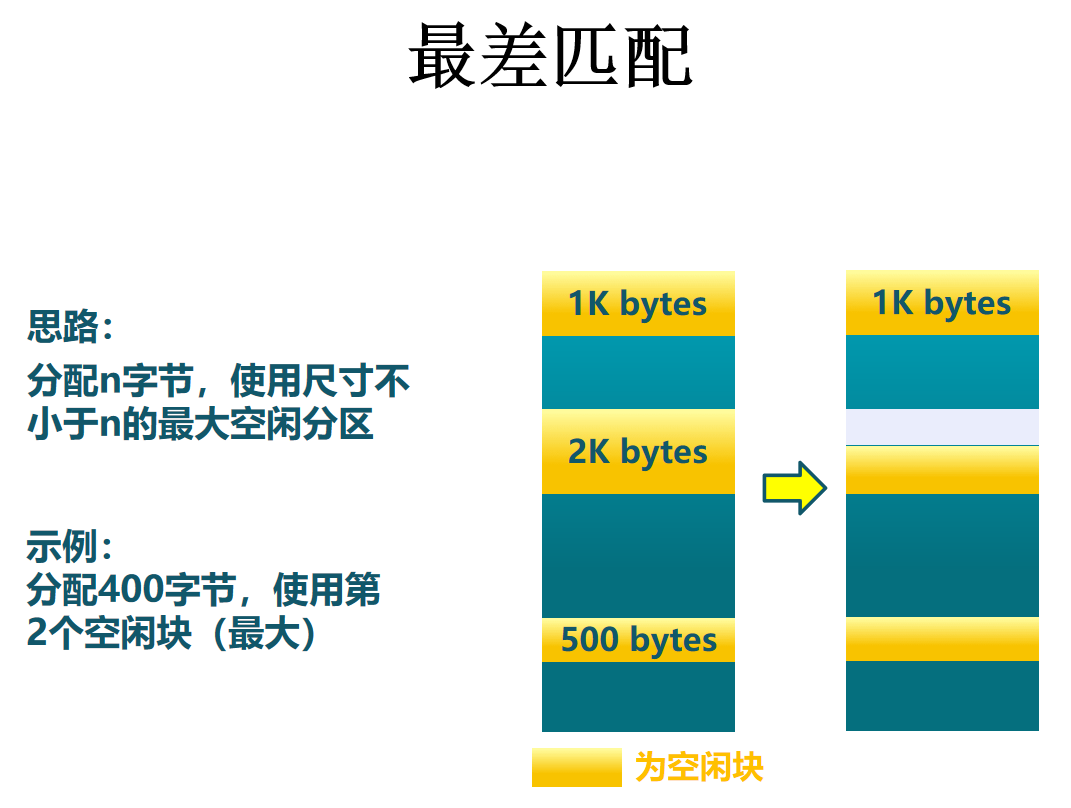
基本不留下小空闲分区,但较大的空闲分区不会被保留。对于最差匹配而言,代码实现上怎么找到最大的内存块?问题:需要内存块从大到小排序,同时每次取完最大的内存块,并将剩余内存放入数据结构中。很显然根据这个描述,应该选择用一个优先队列/堆来实现。
分段机制
编译链接后地址仍然为相对地址(相对于所在段的偏移),装载进内存后地址仍然不变,运行时CPU每次访存时需要额外做一次加法操作,把偏移加上所在段的段基址寄存器,(eg:CS代码段寄存器、DS数据段寄存器和SS堆栈段寄存器),同时还需要进行长度检查,得到物理地址或者虚拟地址,这里取决于使不使用分页机制。段页机制结合使用的时候(现代x86系统),CPU将偏移加上段基址得到虚拟地址,然后再送给MMU进行翻译转换成物理地址,进行实际的访存操作。分段机制在现代操作系统中用得很少,因为每一次访存都需要额外的一次加法,x86使用更多是为了后向兼容。
接下来引入另一种技术:分页技术。内存不够了怎么办?
1 | A;//20K |
理论上来说,这个程序需要size(A)+size(B)+size(C)+size(D)+size(E)+size(F)=190K大小的内存空间,但实际上由于分支判断的缘故,用不到这么多。程序员声明的变量所需的内存跟代码实际执行时实实在在占用的内存不一致,“虚张声势”。
虚拟存储基本思想:按需加载
- 一个或多个进程的程序段、数据段、堆栈段总和可以大于物理存储空间
- 进程中的各段不必完全装入内存,就可启动进程运行
- 操作系统定时将暂时不用的信息换出内存
- 需要时操作系统再将交换区信息换入内存
所以虚拟存储=物理内存+外存(硬盘)
程序员声称需要的内存,并不一定是真正的需要。程序员需要的内存,可以切分成“块”,需要的时候再分配。如何切“块”?多大一块最合适?如何“使用”块?程序员真正需要的时候,怎么可以方便的使用?如何知道某一块内存“真正的需要”?如何不用程序员参与就感知内存被访问或即将被访问?
基于上面的问题,于是给出分页的基本思想:将程序的逻辑地址空间划分成固定大小的页(page)。将物理空间按页的大小划分成页面(page frame),页面可被所有进程共享。分配时,内存中的进程除在一个页面中是连续的,页面间的分配可以不连续。分页后进程的逻辑地址由两部分构成:
- 页号:address / page_size
- 页内地址:address % page_size
物理地址:真正的DRAM;逻辑地址:程序员的幻觉。
页表:为逻辑地址与物理地址建立映射,记录复杂的对应关系,将不连续的物理地址变成了连续的逻辑地址。新的问题:一个页的大小选多大?
可以想到,页面太大页内碎片会增多,降低内存的利用率;页面太小进程的页面数就会增加,页表项增多页表过长(无端联想:路由表)。本质还是计算机科学trade-off的问题,最终大佬们选好了:4K。一个页的大小为4K,因为前向兼容的问题,这个数也一直没有变过,OS霸主说了算。这里放一段“佳话”。
the point is, if you have granularity that is bigger than 4kB, you lose binary compatibility on x86, for example. The 4kB thing is encoded in mmap() semantics. In other words, if you have sector size >4kB, your hardware is CRAP. It’s unusable sh*t. No ifs, buts or maybe’s about it.
——-Linus Torvalds
于是页号 = address / 4096 = address >> 12;页内地址 = addres % 4096,即为地址低12位。
为了支持这个过程,还需要在硬件上进行改动,增加 MMU(Memory management unit)。MMU会检测每一个CPU访存的操作,并发现程序在运行过程中使用了哪个块。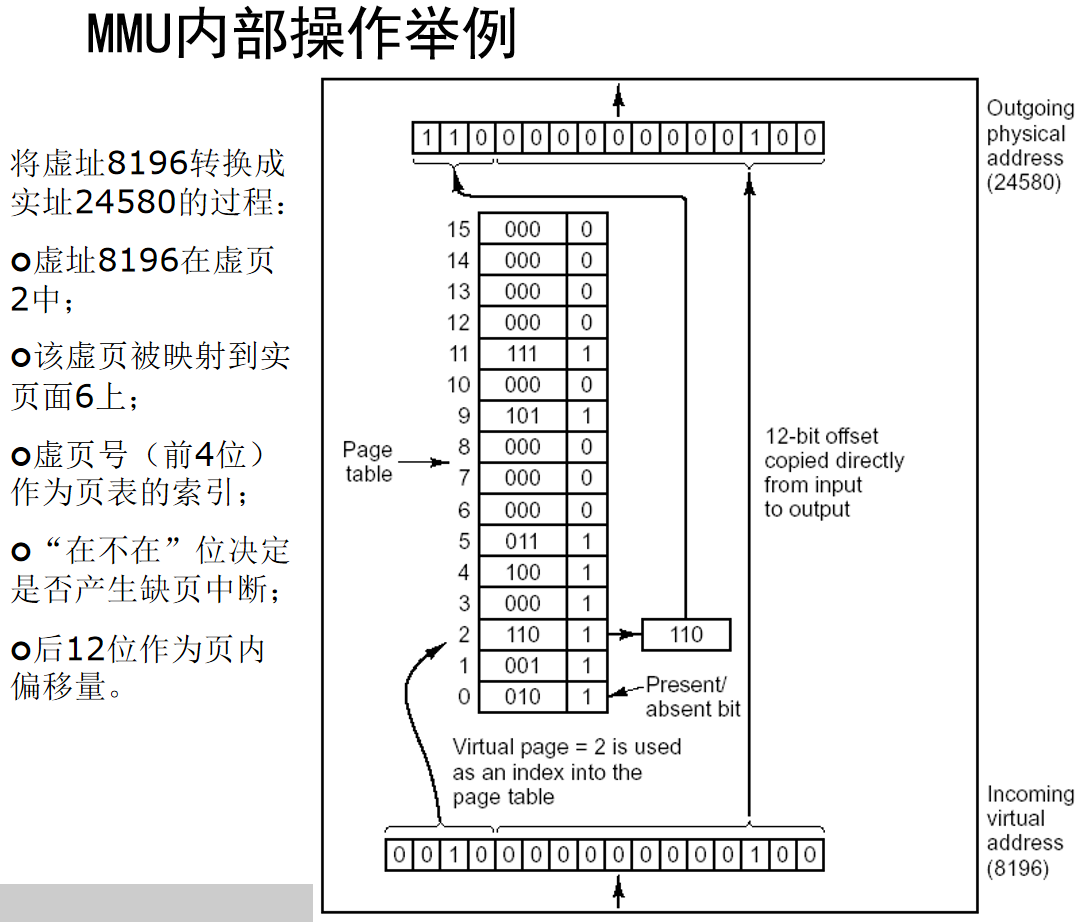
- Page: unit to describe the logical space of process
- Frame: unit to describe the physics space of memory
- Size of Page = Size of Frame =4096
- Page Table: mapping between page and frame
放两个经常搞混的概念:
- 页目录项(Page Directory Entry):页目录项是一级页表中的一个元素。每个页目录项包含指向二级页表的物理地址。
- 页表项(Page Table Entry):页表项是二级页表中的一个元素。每个页表项包含指向实际物理内存页(页框)的物理地址。
多级页表中:以32位系统为例,二级页表所对应的物理页框上,存的即是4字节的地址。查询过程:根据cr3寄存器拿到顶级页表的物理地址,之后则用页目录号乘以4(字节)+cr3寄存器的值,得到页目录项,读取这个地址上的数据,得到存放二级页表起始地址的地址值,即为x。二级页表也是4字节4字节的地址序列。之后类似,将页号(中间10位)乘以4+ x 得到页表项,读取这个地址上的数据即为物理页框号,将页框号与12位的页内偏移相拼接则得到最终的物理地址。
注意:页框号<<12即得到这一物理页的起始地址。
页表存在内存中,这意味着对于32位系统。访问一次内存附赠了两次到内存查询页表(对应两级页表结构)的操作,实际上效率更低了。根据程序的局部性原理,每次访存也需要访问两次页表,使用cache(TLB)来加速查询页表的操作
虚拟地址:程序员“臆想”的空间,是OS帮开发人员制造的“幻觉”。同样的,CPU拿到的也是虚拟地址,被MMU所蒙蔽。OS就像一个骗子一样,告诉程序员有4G大小的内存空间,实际上并没有这么大。
MMU在进行地址翻译的时候,先从satp寄存器(RISCV)或者说cr3寄存器(x86)中拿到多级页表树的“树根”,之后借由树根逐级向下翻译最终找到物理页。
当有某个进程需要更多的页框时,OS负责找到一个空白的页框,将这个页框交给目标进程,并修改该进程的页表。新的问题,系统需要知晓所有空白页框在哪儿。为了高效定位空白页框,系统需要维护一张表,该页表中记录了每个页框的使用情况,每次内存页的申请与释放,进程的销毁都会修改这张表,这张页表管理的是物理地址。因此,系统中存在两种“页表”,一种为每个进程使用,叫page_table,另一个供系统整体使用,叫page_free_list。进程的整个运行过程中,都在使用虚拟地址,应用程序无法触及物理地址,也就无法影响其他进程。只要页表不冲突,两个进程不会碰到同一个物理地址。所以不存在一个进程访问到了不属于自己虚拟地址空间映射的物理页。因为在初始化的时候由OS找到一个空白物理页并在页表中建立映射,随即操作系统就修改了page_free_list。这一个物理页就不会再分配给其他进程。
创建进程的步骤:
- 分配一级页表(页目录表)
- 将一级页表的物理地址放入CR3中
- 应用程序加载,在虚拟地址中载入分段信息和部分数据、指令。依据编译链接的结果,这些信息放在程序二进制头中;建立虚拟地址与文件内的物理偏移量的对应关系。
- 进程创建完成,将PC转去main以执行程序
- 取指令数据中引发缺页,OS加载新的数据
- 如果该虚拟地址的页表不存在,则需创建页表
引发缺页中断的两种情况(本质上都是“缺页”,要的物理页不在DRAM中):
- 页表中没有映射关系:进程首次尝试访问某个虚拟地址时,页表项中没有这个映射关系,需要拿一个物理页帧来建立映射,并在页表和TLB中记录。
- 物理页被换出到磁盘:物理页存在,页表项中有记录,但物理页被换到了磁盘上,需要换回来。
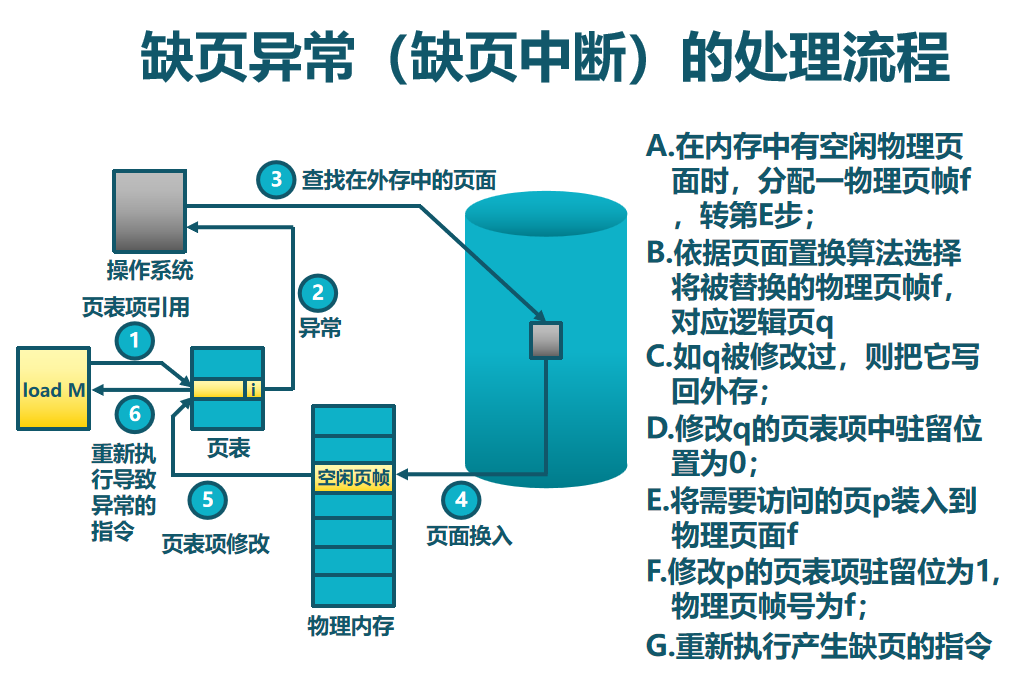
页面置换算法这里不列了,但有一个有意思的东西。Belady现象:分配的物理页面数增加,缺页次数反而升高的异常现象。
LFU、LRU、FIFO以及时钟置换等算法针对于给定进程的页面数量,选择换入换出哪个页。工作集置换算法则基于工作集,动态调整分配给进程的物理页数量。
工作集的概念:W(t, x)是指在当前时刻t前的x时间窗口中的所有访问页面所组成的集合,是进程在运行过程中固有的性质。
常驻集的概念:在当前时刻,进程实际驻留在内存当中的页面集合,取决于系统分配给进程的物理页面数目和页面置换算法。常驻集是工作集的超集时,缺页较少
抖动问题
进程物理页面太少,不能包含工作集;造成大量缺页,频繁置换;进程运行速度变慢。产生抖动的原因:随着驻留内存的进程数目增加,分配给每个进程的物理页面数不断减小,缺页率不断上升。操作系统需在并发水平和缺页率之间达到一个平衡,选择一个适当的进程数目和进程需要的物理页面数。即需要处理好常驻集、工作集和进程数量以及空闲内存的关系。
设备管理
设备是计算机系统中差异化最大的部分,每个设备都有自己复杂的逻辑,而OS的目标是让上层软件尽可能少的感知这些差异。
如何及时发现设备上的数据?
- 等待并轮询,CPU 需要不断地测试I/O设备。问题:浪费CPU资源,这跟IPC里忙等待是一样的。同时I/O又是慢速设备,CPU的绝大部分时间都在测试I/O设备是否已经完成数据传输,二者只能串行执行。通俗点说,就是CPU一直问设备:你准备好了没有?
- 设备处理完成后产生中断来通知CPU,通俗说就是设备准备好了再喊CPU。这种情况下CPU和I/O设备间可以并行工作,CPU只需收到中断信号后处理即可,大大提高了CPU利用率。
但是频繁的中断一样会影响CPU的执行效率,上下文切换的开销依旧不小。所以考虑引入DMA。DMA控制方式的基本思想是在外设和内存之间开辟直接的数据交换通路。即不需要经过CPU的干预即可访问内存。
如何传输这些数据?
- 由CPU发起,逐字节传输
- 由DMA设备代为发起,以块为单位传输
下面是三种不同的控制方法: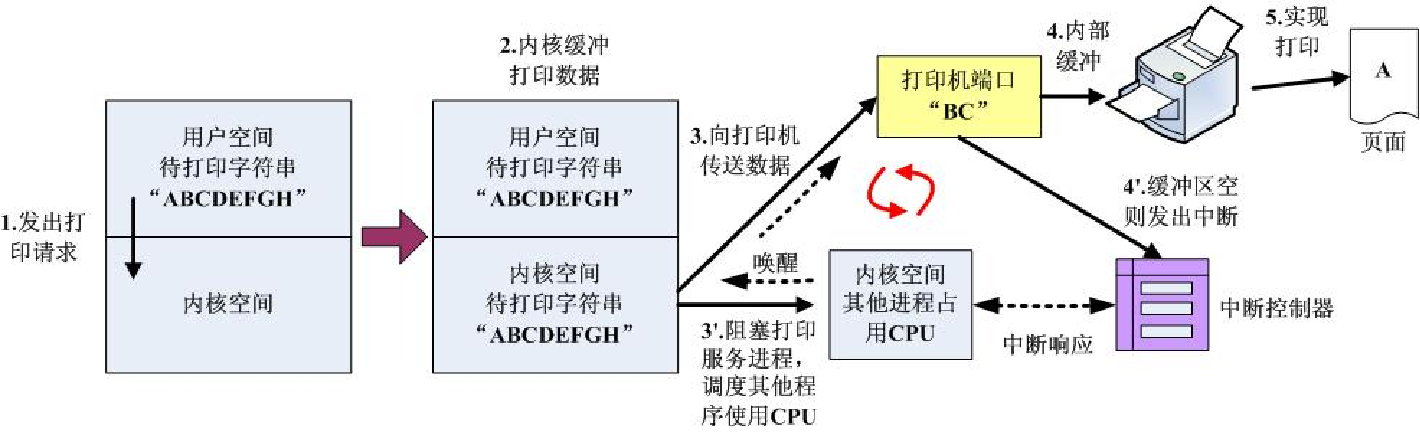
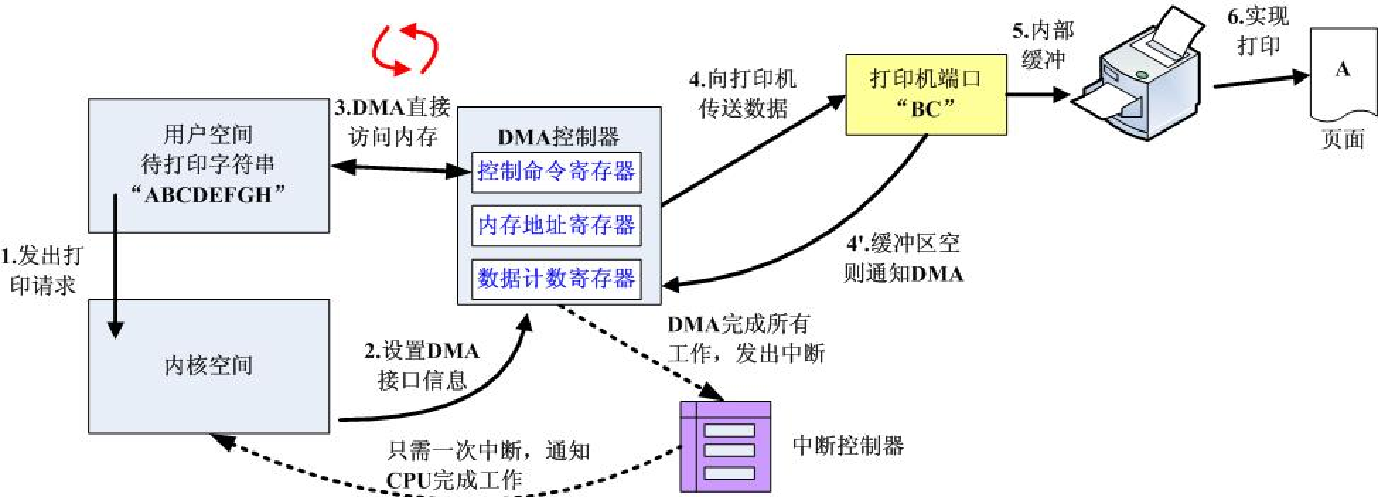
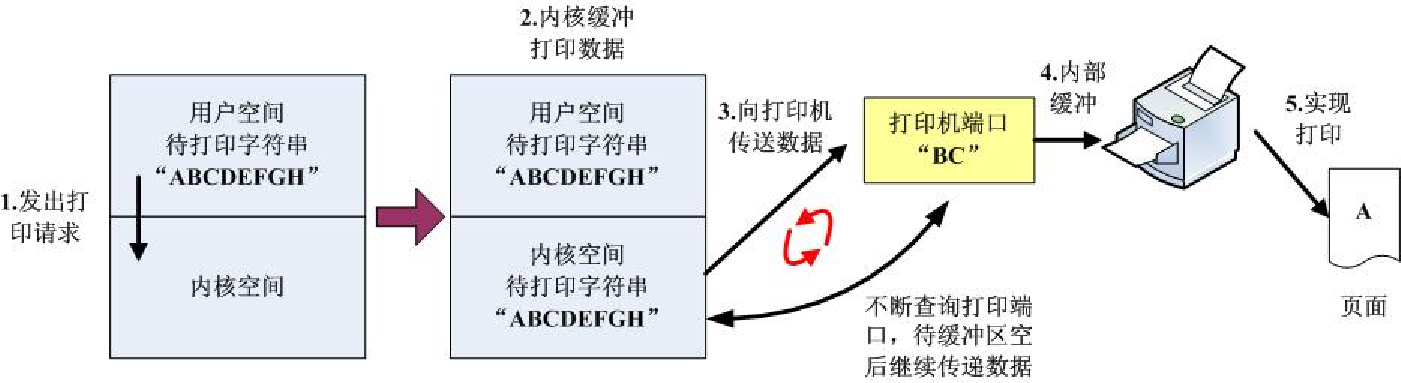
之前说的设备“准备好了没有”,对应上图就是打印机的缓冲区是否为空,而打印机则负责把缓冲区的内容打印出来。第三种方式则是借助DMA,如果缓冲区为空则I/O通知DMA,DMA又直接从内存读取数据。当DMA完成所有工作后,再产生中断信号,告诉CPU任务已完成。所以仅在一个或多个数据块的开始和结束时,才需要CPU干预。
总结
给一个OS所做工作的总结:
- OS在系统启动的时候频频出镜,接管所有的硬件资源并建立索引
- 中断向量表、上下文数据结构、可用物理内存
- OS启动成功后,创建一个进程,从此控制权交到用户空间
- 用户空间的进程都是通过创建进程的系统调用复制而来,新的进程利用mmap或者其他调用构建自己的地址空间
- 在构建好的空间中,进程的运行就是用户程序的指令流填入处理器中,这个过程与操作系统无关
- 中断(外设)和异常(syscall, page fault)是OS出场的主要时机
- 时钟中断是主要的调度源之一
- 优先级、时间片轮转、先进先出。。。。
- 缺页异常是主要的页面转换驱动力
- LRU,FIFO,时钟调度法。。。。
- 系统调用是主要的进程状态变化驱动力
- 运行变阻塞
- 外设的中断是另一个进程状态变化驱动力
- 阻塞变就绪
操作系统本身的东西至此结束,下面给一些特定操作系统上的概念。
Windows 操作系统
恶意代码课程的学习需要,被迫了解。放几个我认为比较重要的东西吧。
Windows API:Windows应用程序编程接口。这也就是之前所提到的,操作系统所提供给上层应用的函数接口,比如:Socket相关的函数、CreateProcess(……) 之类的函数。事实上在C++中,对一些接口又进行更高层次的封装。比如C++11 中的 thread 库,实现了操作系统的无关性,上层应用不需要关心是在哪个操作系统平台上进行的编程(比如在Linux下和在Windows下使用Socket编程使用的是不同的编程规范,因为操作系统提供了不同的接口),应用开发者通过调C++标准库函数即可进行编程,这些库函数语法也更符合现代C++的编程风格,而不是去学习和使用 HANDLE、LPVOID 之类的关键字。当然,这也提高了代码的可移植性。
句柄
句柄:是一个指向资源的引用,如文件或窗口等,这里统称为“对象”。如下图: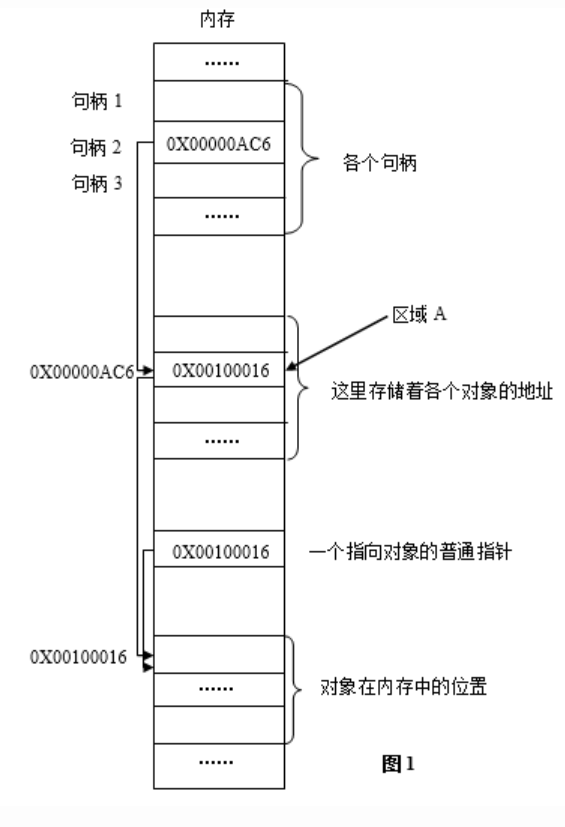
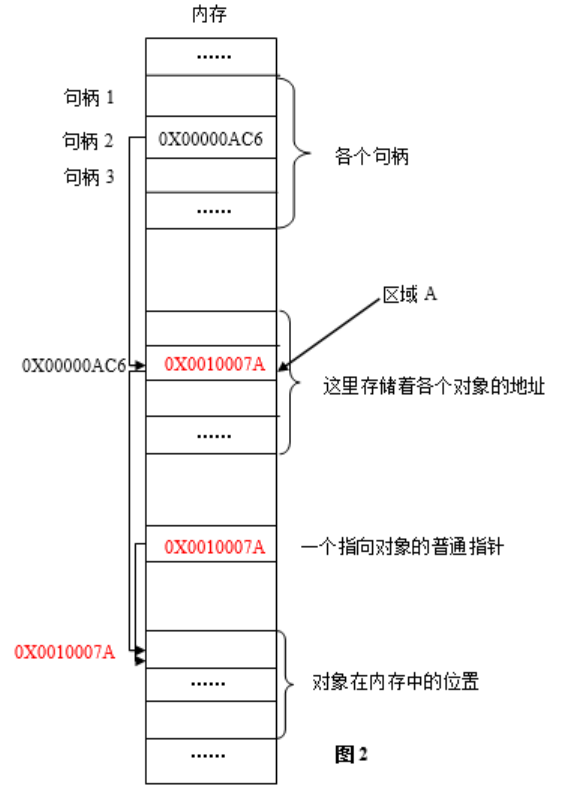
其中,图1是程序运行到某时刻时的内存快照,图2是程序往后运行到另一时刻时的内存快照。红色部分标出了两次的变化。简单解释:因为虚拟内存的原因,进程的某一数据装入内存后,可能被换出到外存,当再次需要时,再装入内存。两次装入的地址绝大多数情况下并不相同,同一对象在内存中的地址会变化。程序怎么才能准确地访问到对象呢?为了解决这个问题,Windows引入了句柄。
系统为每个进程在内存中分配一定的区域,用来存放各个句柄(x86中即32位的无符号整数)。每个32位无符号整型值相当于一个指针,指向内存中的另一个区域(图中区域A)。而区域A中存放的正是对象在内存中的地址。当对象在内存中的位置发生变化时,区域A的值被更新,变为当前时刻对象在内存中的地址,而在这个过程中,区域A的位置以及对应句柄的值是不发生变化的。即:有一个固定的地址(句柄),指向一个固定的位置(区域A),而区域A中的值可以动态地变化,它时刻记录着当前时刻对象在内存中的地址。无论对象的位置在内存中如何变化,只要掌握了句柄的值,程序就可以找到区域A,进而找到该对象。而句柄的值在一次程序运行期间是绝对不变的,这就是以不变应万变,按图索骥,顺藤摸瓜。当然,第二次打开该程序,句柄的值一般就不在这个固定位置上了。
数值上,句柄是一个32位无符号整型值;逻辑上,相当于指针的指针;形象理解上,是Windows中各个对象的一个唯一的、固定不变的ID;作用上,Windows使用句柄来标识诸如窗口、位图、画笔等对象,并通过句柄找到这些对象。通过句柄,可以调用Windows API进行对象的操作,但不能像使用指针那样,做其它的事,这就像学校发的ID号你可以读取,但不能修改。这个ID号是Windows生成的。
照理说,这里应该直接去扒微软官网中给出的句柄结构体定义,但实在不想去看那一大堆DWORD、lpxxx变量。烦,非常烦,烦死了。有这时间不如直接去学优雅的Linux
DLL
说这个问题前,先说一下链接的问题。根据链接时间的不同,链接方法有如下分类:
静态链接(Windows不常用,在UNIX和Linux程序中比较常见)
- 当一个库被静态链接到可执行程序时,所有这个库中的代码都会复制到可执行程序中去。PE文件头里没有链接库的信息(也就相当于说是,直接把所有的头文件中的代码都相当于是自己写的代码)
- 可执行程序体积大
- 占用内存空间
运行时链接(在合法程序中不流行,但是恶意代码中常用,尤其是在加壳或者混淆的时候)
- 只有当需要使用函数时,才会链接到库
- 最常用的函数
- LoadLibrary:将动态链接库动态的从硬盘加载到病毒的内存空间
- GetProcAddress:从动态链接库中找到对应函数的调用地址
动态链接(最常见的)
当代码库被动态链接的时候,宿主操作系统会在程序被装载时搜索需要用到的代码库;如果程序调用了被链接的函数,这个函数会在代码库中执行
简单来说,静态链接类似于C语言中的#include,预定义的时候就把原始代码原封不动拷贝过去。静态链接是在程序的编译链接阶段发生的过程,将程序所需的所有代码和库函数合并到一个独立的可执行文件中;动态链接则引用外部库:动态链接的程序在磁盘上不包含它所使用的库的代码。相反,它包含了对这些库的引用,这些库在程序运行时被加载到内存中。类比一下,这俩就像引用url时本地链接和网络链接一样。而运行时链接更多由程序自己来与链接库交互,动态链接则由OS来代劳。
DLL,全称为动态链接库 Dynamic Link Library,可以理解成一个包含多个函数函数库,但它本身是不能直接运行的,需要附加到现有的进程中才可以运行。可以通过命令行键入以下命令来运行库里的某个函数:
1 | rundll32.exe dll-name,function-name/#5, arg1, arg2 |
具体的DLL加载流程:
启动程序时,操作系统加载器读取PE文件:执行一个EXE文件时,操作系统的加载器首先读取PE文件头,确定程序的各个部分在内存中的布局。
加载器处理IAT:加载器检查导入地址表(IAT),这个表最初包含对需要调用的DLL函数的引用,这些引用可能是函数的名称或序号。
加载所需的DLL:如果所需的DLL还没有加载到内存中,加载器将其加载进来。这个过程包括找到DLL文件,将其内容加载到内存中,进行必要的重定位,并处理DLL自己的导入(DLL本身可能依赖其他DLL)。
更新IAT:加载器现在知道DLL函数的实际内存地址,它更新IAT中的每个条目,将原来的引用替换为这些函数的实际虚拟内存地址。
程序执行:一旦所有的DLL都被加载并且所有的IAT条目都被更新,程序就开始执行。当程序需要调用某个DLL中的函数时,它会查找IAT中的对应条目,通过那里记录的地址跳转到函数的实际代码。
DLL(动态链接库)vs EXE(可执行文件):
- 它们都使用相同的PE文件格式。
- 一个PE文件头中的标志位(这里不想给了)指明了文件是DLL还是EXE。
- 相比EXE,DLL通常有更多的导出函数(供其他程序调用)和较少的导入函数(调用其他程序的函数)。
- DLL的主函数叫做DllMain,这个函数不是用来导出的,而是在PE头部指定为入口点。当库被加载或卸载时,系统会调用这个函数。
上面提到的 Windows API 一般封装在Kernel32.dll、User32.dll等动态链接库中。
注册表
存储Windows系统和应用程序的设置信息。可以理解成Windows的核心数据库,包含Windows的启动信息、硬件的配置和状态信息、系统的状态信息、应用程序的初始条件、首选项、卸载数据等。注册表的基本元素:
- 键(Key): 类似于文件夹
- 值(Value): 类似于文件
一个键可以有一个或者多个值一个键也可以包含多个子键。五个根键(Root Key):
| Root Key | Description |
|---|---|
| HKEY_CLASSES_ROOT | 存储Windows可识别的文件类型的详细列表,以及相关联的程序。 |
| HKEY_CURRENT_USER | 存储当前用户设置的信息。 |
| HKEY_LOCAL_MACHINE | 包括安装在计算机上的硬件和软件的信息。 |
| HKEY_USERS | 包含使用计算机的用户的信息。 |
| HKEY_CURRENT_CONFIG | 这个分支包含计算机当前的硬件配置信息。 |
The WinINet API
简单来说就是在传输层上,Windows又封装了一套用来直接处理http/ftp等应用层协议的windows API。不想放代码,什么时候实际用到了再说,就这样吧。
服务
这东西很像Linux下的守护进程。
后台运行:服务在没有用户界面的情况下在后台运行,这意味着它们在用户登录前就可以启动,并在用户注销后继续运行。
长期运行:服务通常设计为长时间运行,而不是短期任务。它们可以被配置为在系统启动时自动启动。
系统级任务:服务常用于执行系统级任务,如日志记录、系统监控、网络服务和硬件交互。
有好几种服务类型,这里给一个经常被病毒用来做文章的:WIN32_SHARE_PROCESS
WIN32_SHARE_PROCESS是Windows服务中的一个类型,指的是可以将多个服务共享同一个进程的服务类,其代码通常存储在动态链接库(DLL)中,而不是独立的可执行文件(EXE)。当服务启动时,它会被加载到一个宿主进程中。共享单一进程:这种类型的服务通常会与其他服务共享同一个进程。在Windows系统中,许多官方服务就是通过名为svchost.exe的宿主进程来共享的。svchost.exe是Windows中的一个系统进程,负责托管那些标记为WIN32_SHARE_PROCESS的服务。由于多个服务可以共享同一个svchost.exe实例,因此这可以提高效率并节省系统资源。这意味着一个svchost.exe进程可能同时运行多个服务。这就不难想到,恶意软件可以利用WIN32_SHARE_PROCESS服务类型,名正言顺地让自己隐藏在正常的svchost.exe进程中。由于svchost.exe是Windows操作系统的正常组成部分,并且通常有多个svchost.exe实例在运行,因此更难以从中识别出恶意行为。WIN32_OWN_PROCESS 服务类型则是独立运行在进程中的服务。
Native API
Native API是Windows操作系统内部使用的API,它提供了操作系统更底层的服务。这东西是不开源的,微软官网上没有相关的文档,能查到的 Native API 也是黑客反汇编得到的,函数一般以Nt开头。这也意味着,有一些被扒出来的 Native API 很可能随着 Windows 版本更新就无法使用了。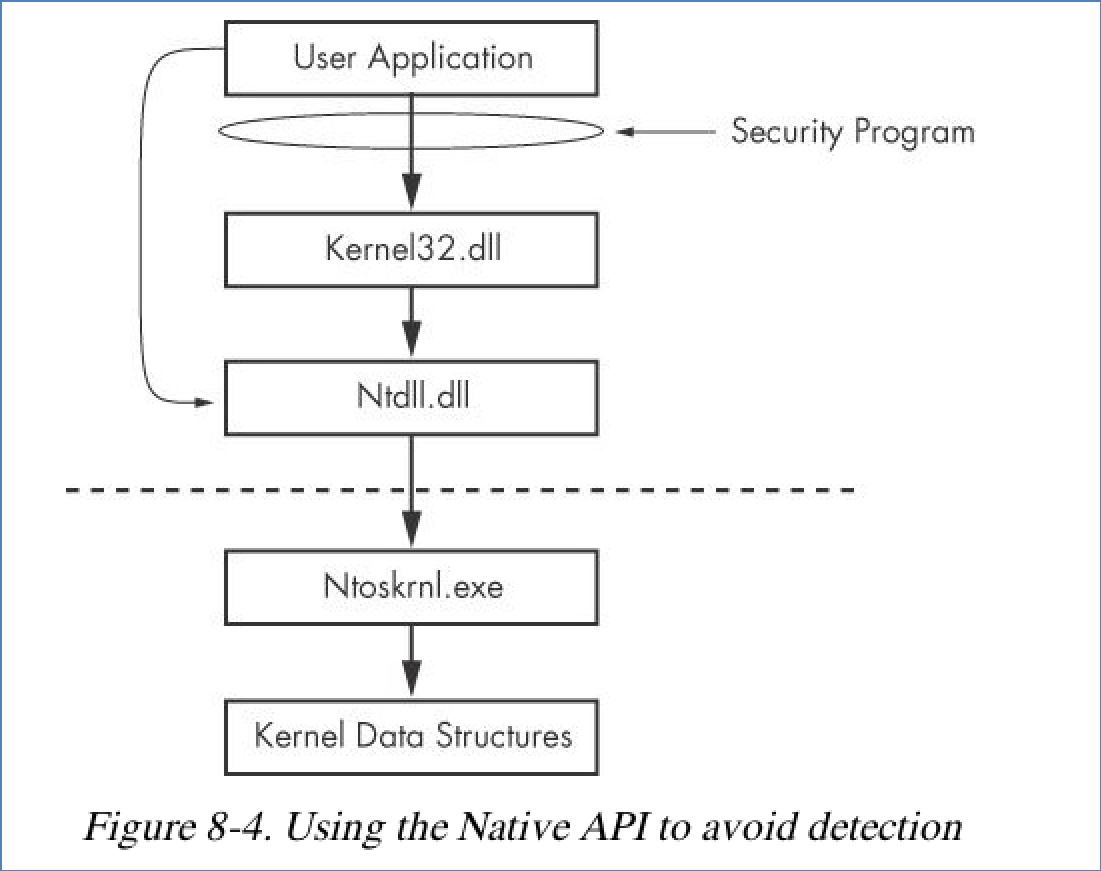
从上面的图可以看到,杀毒软件多针对 Windows API,而使用 Native API 则可以绕过这方面的检测。Native API 对应上图的 Ntdll.dll 库。当然,Native API 仍然是用户空间里使用的函数。
SSDT
SSDT(System Service Dispatch Table):系统服务描述符表,它用来查询处理系统调用,它用来查询处理系统调用的特定函数。简单来说,SSDT就是Native APi 到具体某一个系统调用的映射。这个逻辑跟IDT(中断向量表)有点像,也是根据上层传入的参数(比如一个中断类型或者说API编号)来分发到不同的处理函数,本质上就是一个函数指针数组。SSDT是映射到一个内核函数中,IDT是映射到一个ISR上,用来处理具体的中断。举一个用户输出操作的例子,比如在屏幕上显示文字,整个调用流程涉及多个层次,具体如下:
- 应用程序层(用户空间):
应用程序使用Win32 API函数,如WriteConsole(),来请求输出操作。例如,C++程序可能会调用std::cout来输出到控制台,这最终会调用相关的Win32 API。 - Win32 API层(用户空间):
Win32 API函数接收请求,并处理参数,准备进行更深层次的调用。Win32 API内部将调用转换为一个或多个Native API调用。比如WriteConsole()可能会在内部转换为一个调用NtWriteFile()的Native API。 - Native API层(用户空间):
Native API准备好必要的参数和数据结构,通过一个特殊的机制(如在x86架构上的syscall指令)触发系统调用,请求内核模式下的服务。 - 系统调用和SSDT(内核空间):
CPU接收到系统调用请求,触发中断,完成权限提升,从用户态进入内核态。之后内核使用SSDT来确定对应的内核函数。 - 内核处理函数(内核空间):
选定的内核函数执行实际的输出操作。这个例子可能涉及到与显示驱动程序交互,最终将文字渲染到屏幕。操作完成后结果返回给调用者。 - 返回用户模式(用户空间):
内核完成操作后,控制权返回到用户模式,Native API和Win32 API层可能会进行一些清理工作。 最终,控制权返回到应用程序,屏幕上出现“hello world!”
总的来说,Windows下的函数调用也是层层封装的过程,这个过程中的WinAPI可以跟 kernel32.dll相对应,Native API可以跟Ntdll.dll相对应,内核API可以跟Ntoskrnl.exe对应。操作系统层层的函数封装抽象自然有它设计的道理和精髓,但似乎也变相地在各个层次上为病毒提供了操作的空间,只能说夜长梦多。对于病毒而言,SSDT就有可乘之机。病毒把映射所调用的内核函数入口地址改成其所指定的地址,之后就会按照病毒指定的函数继续执行程序,然后再调用原始的系统服务,用户空间的程序则完全不知情。对于IDT其实也是一样的,这种技术一般称为Hook。
Linux 操作系统
重头戏来了,移步看另一篇Blog吧:linux学习之路
